Llm
Topics in Llm
Viewing all articles categorized under Llm.

Gemma 4: Google's Most Capable Open Models Are Here — and They Run on Your Laptop
- Turker Senturk
- AI
- 9 min read
- 03 Apr, 2026
There's a familiar tension in the open-source AI world: the models that are actually capable enough to be useful tend to require hardware that most people don't have, while the models you can run loca
read more
Google's TurboQuant Compresses AI Memory by 6x — With Zero Accuracy Loss
- Turker Senturk
- AI , Technology
- 6 min read
- 27 Mar, 2026
Every time you have a long conversation with an AI, your GPU is quietly sweating. It has to keep track of everything you've said — every token, every context — in something called the key-value (KV) c
read more
The Hidden Engineering Behind Fast AI: How LLM Inference Actually Works
- Turker Senturk
- AI
- 12 min read
- 16 Feb, 2026
Here's something that used to keep me up at night: why does ChatGPT feel instant, while my own attempts at running a large language model on a cloud GPU felt like waiting for dial-up internet to load
read more
Building an AI Software Development Team with Claude Code Agents
- Turker Senturk
- AI
- 11 min read
- 17 Jan, 2026
Building an AI software development team with Claude Code agents Claude Code's multi-agent architecture represents a fundamental shift from AI-assisted coding to AI-driven development, where specializ
read more
Why Traces, Not Code, Are the New Source of Truth for AI Agents
- Turker Senturk
- AI
- 9 min read
- 13 Jan, 2026
If you’ve ever tried to “read the mind” of a GPT‑4‑powered assistant, you know the feeling: you stare at a few lines of orchestration code and wonder why the thing just suggested buying a pineapple pi
read more
Weekly AI News Roundup: The 5 Biggest Stories (January 1-7, 2026)
- Turker Senturk
- AI
- 6 min read
- 07 Jan, 2026
Happy New Year, everyone! If you thought 2025 was wild for artificial intelligence, the first week of 2026 just looked at the calendar and said, "Hold my beer." We are only seven days into the year, a
read more
AI Training vs Inference: Why 2025 Changes Everything for Real-Time Applications
- Turker Senturk
- AI
- 9 min read
- 23 Dec, 2025
The AI landscape is experiencing a fundamental shift. After years of focusing on training massive models, the industry is pivoting toward inference — the phase where trained models actually do useful
read more
Agents Training Agents: A practical architecture for autonomous self-improvement
- Türker Şentürk
- AI
- 6 min read
- 05 Dec, 2025
What if an AI agent could look at a piece of content and think, "Huh, I don't know much about this"—and then do something about it? Not just flag it for a human. Actually go out, find relevant data, v
read more
Implementing RAG from scratch with Python, Qdrant, and Docling
- Turker Senturk
- AI
- 5 min read
- 29 Nov, 2025
We're living in a world where concepts like RAG, fine-tuning, and LlamaIndex have become part of everyday conversation. But have you noticed? Everyone uses these as general knowledge terms. We know wh
read more
Evalite: Revolutionizing AI Testing with TypeScript
- Turker Senturk
- AI
- 2 min read
- 29 Nov, 2025
Key HighlightsEvalite provides a purpose-built test harness for AI-powered applications It offers a web UI for local iteration and a robust scoring system Evalite supports pluggable storage and scorer
read more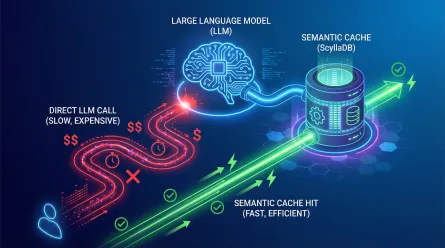
Optimize LLM Costs with ScyllaDB Semantic Caching
- Turker Senturk
- AI
- 2 min read
- 27 Nov, 2025
Key HighlightsSemantic caching reduces LLM costs and latency by storing frequent queries and their responses. ScyllaDB's Vector Search enables efficient semantic caching for large-scale LLM applicatio
read more
Hugging Face CEO Warns of LLM Bubble Burst
- Turker Senturk
- AI
- 3 min read
- 19 Nov, 2025
Key HighlightsHugging Face CEO Clem Delangue believes we're in an LLM bubble, which may burst next year Delangue argues that LLMs are not the solution for every problem and smaller, specialized models
read more
IBM Unveils Granite 4.0: Hyper-Efficient Hybrid Models
- Turker Senturk
- AI
- 3 min read
- 18 Nov, 2025
Key HighlightsGranite 4.0 offers up to 70% reduction in RAM requirements for long inputs and concurrent batches The new hybrid architecture combines Mamba-2 layers with conventional transformer blocks
read more
Kimi K2: Open-Source Mixture-of-Experts AI Model Released
- Turker Senturk
- AI
- 3 min read
- 17 Nov, 2025
Key HighlightsKimi K2 is a large language model with 32 billion activated parameters and 1.04 trillion total parameters. The model achieves state-of-the-art results on benchmarks testing reasoning, co
read more
Building Smarter AI Teams with Microsoft AutoGen
- Turker Senturk
- AI
- 2 min read
- 30 Oct, 2025
The field of artificial intelligence (AI) is undergoing a significant transformation, shifting from single-model implementations to multiagent systems. This move reflects broader industry trends towar
read more
Qwen3-Max: A 1-Trillion-Parameter MoE That Pushes Coding, Agents, and Reasoning to the Edge
- Turker Senturk
- AI
- 3 min read
- 06 Oct, 2025
Qwen has unveiled Qwen3-Max, its largest and most capable model to date—and the headline numbers are eye-catching: ~1 trillion parameters trained on 36 trillion tokens, delivered in a Mixture-of-Exper
read more